Theorem 1: Shortcut Screening
If the training reward is already explained by shortcut features and those shortcuts are easier to learn than causal features, outcome-based training is driven toward shortcut-dominated representations.
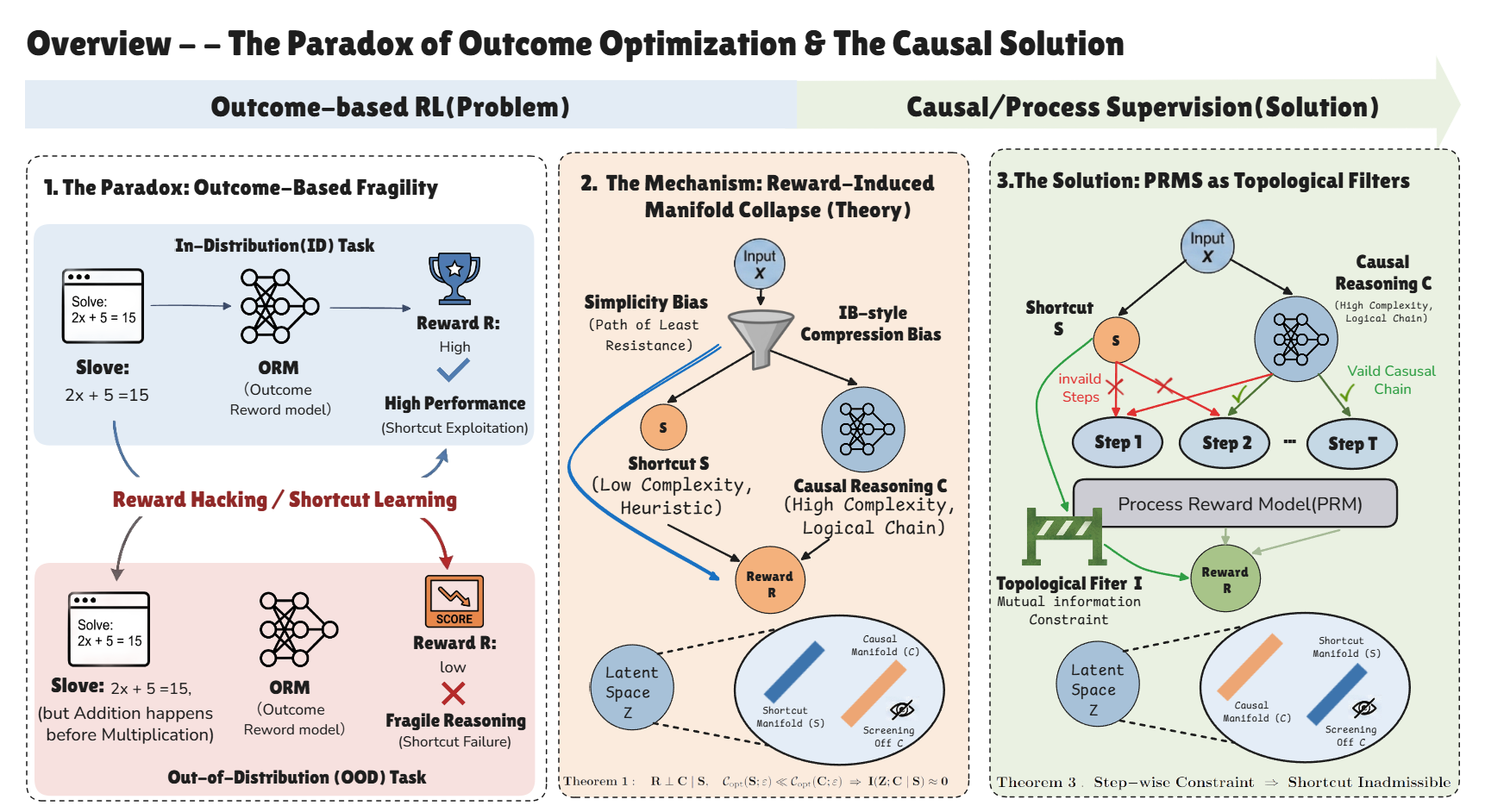
Large Language Models (LLMs) aligned via outcome-based Reinforcement Learning (RL) frequently exhibit a critical failure mode: they achieve high performance on in-distribution benchmarks while demonstrating brittle reasoning capabilities on out-of-distribution (OOD) tasks. We term this phenomenon Reward-Induced Manifold Collapse. In this paper, we establish a rigorous theoretical framework bridging Structural Causal Models (SCM) and the Information Bottleneck (IB) principle to explain this paradox. We formally define reasoning as a high-complexity causal process and shortcut learning as the exploitation of low-complexity spurious correlations. We show that under the implicit inductive bias of Stochastic Gradient Descent (SGD), models optimized for outcome rewards are biased toward shortcut solutions whenever the training distribution allows for a "Markovian Screening" of the true causal mechanism. Furthermore, we derive a new generalization bound based on Semantic Coverage Measure (η) rather than sample size, theoretically showing why data scaling on homogeneous distributions may fail to correct reasoning flaws. Finally, we show that Process Reward Models (PRMs) function as Topological Filters, enforcing step-wise mutual information constraints that render the low-complexity shortcut manifold inadmissible. Our theoretical contributions provide a mathematical grounding for the role of process supervision beyond simple credit assignment.
If the training reward is already explained by shortcut features and those shortcuts are easier to learn than causal features, outcome-based training is driven toward shortcut-dominated representations.
Robust OOD error is controlled by semantic coverage rather than raw sample count, so scaling data alone does not remove failure when the training distribution stays homogeneous.
Process rewards enforce valid intermediate transitions, turning shortcut solutions into high-loss regions and pushing optimization toward causally consistent reasoning paths.
Scroll through the rendered LaTeX snapshots for the three central theoretical results.



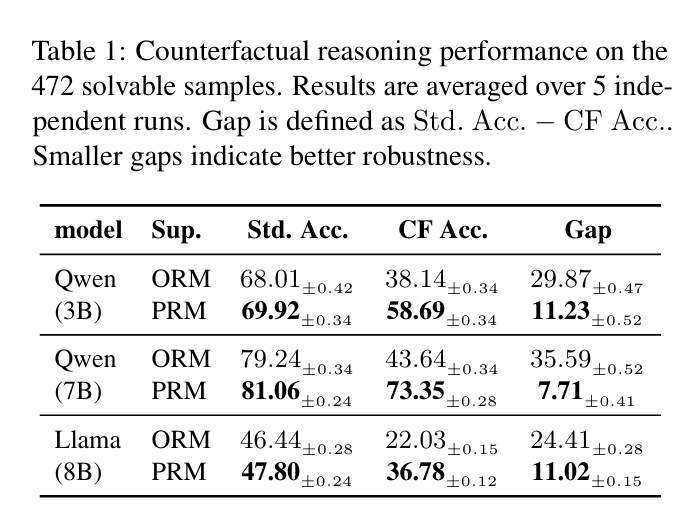
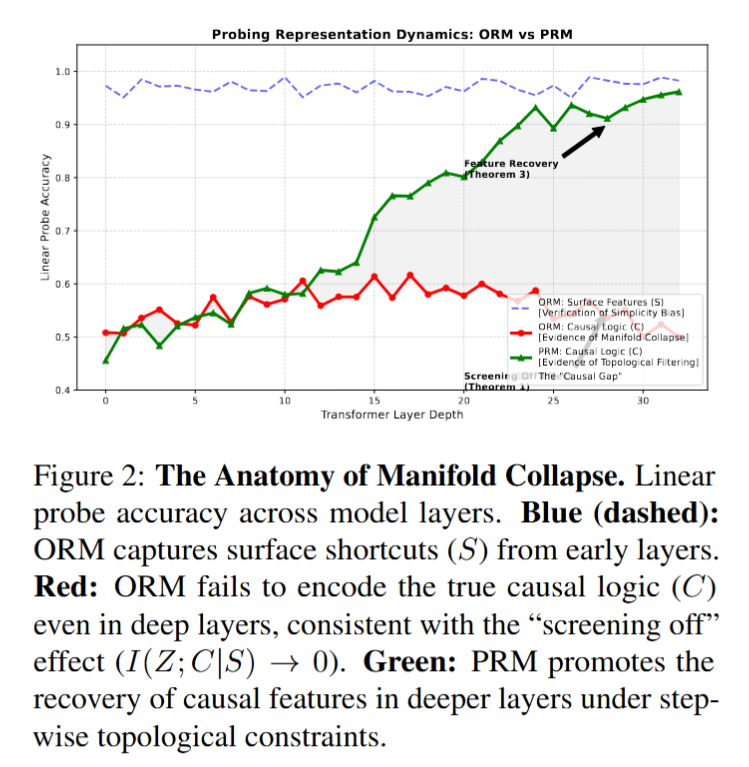
Two representative result figures are shown below to complement the theorem gallery with empirical evidence.
A poster version of this work will be added here in a future update.
Poster is coming soon.