Abstract
Current benchmarks are inadequate for evaluating progress in reinforcement learning (RL) for large language models (LLMs). Despite recent benchmark gains reported for RL, we find that training on these benchmarks' training sets achieves nearly the same performance as training directly on the test sets, suggesting that the benchmarks cannot reliably separate further progress. To study this phenomenon, we introduce a diagnostic suite and the Oracle Performance Gap (OPG) metric that quantifies the performance difference between training on the train split versus the test split of a benchmark. We further analyze this phenomenon with stress tests and find that, despite strong benchmark scores, existing RL methods struggle to generalize across distribution shifts, varying levels of difficulty, and counterfactual scenarios: shortcomings that current benchmarks fail to reveal. We conclude that current benchmarks are insufficient for evaluating generalization and propose three core principles for designing more faithful benchmarks: sufficient difficulty, balanced evaluation, and distributional robustness.
Analysis Framework & Key Results
The Oracle Performance Gap (OPG). To audit the validity of current benchmarks, we introduce the OPG metric. Unlike standard generalization gaps, OPG measures the discriminative power of a test set by comparing a model trained on the training data against an "Oracle" model (fine-tuned explicitly on the test set).
Experiment Setup. We evaluated Qwen2.5 (3B & 7B) across four benchmarks: MATH, GSM8K, HeadQA, and DeepScaler. We systematically compared baselines, Standard SFT, and RL-tuned models against their respective Oracle upper bounds to isolate the effects of the fine-tuning paradigm.
Finding: The Vanishing Generalization Gap. Our analysis reveals a stark contrast between paradigms. While SFT models exhibit a large and expected OPG (indicating valid generalization challenges), this gap collapses to near-zero for RL-trained models. This suggests that for RL, the classical assumption that "unseen" test data is a sufficient measure of generalization no longer holds.
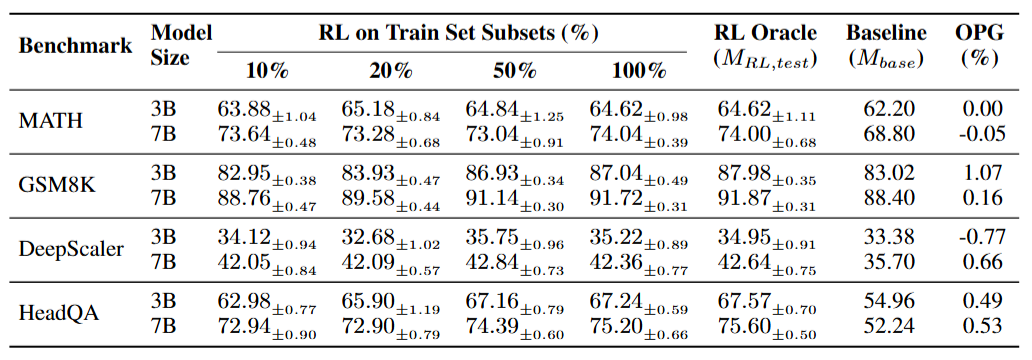
Table 1: Benchmark Limitation. Comparison of RL models on training subsets vs. the Oracle model. The OPG (gap) is negligible, indicating RL agents effectively "memorize" the test distribution patterns.
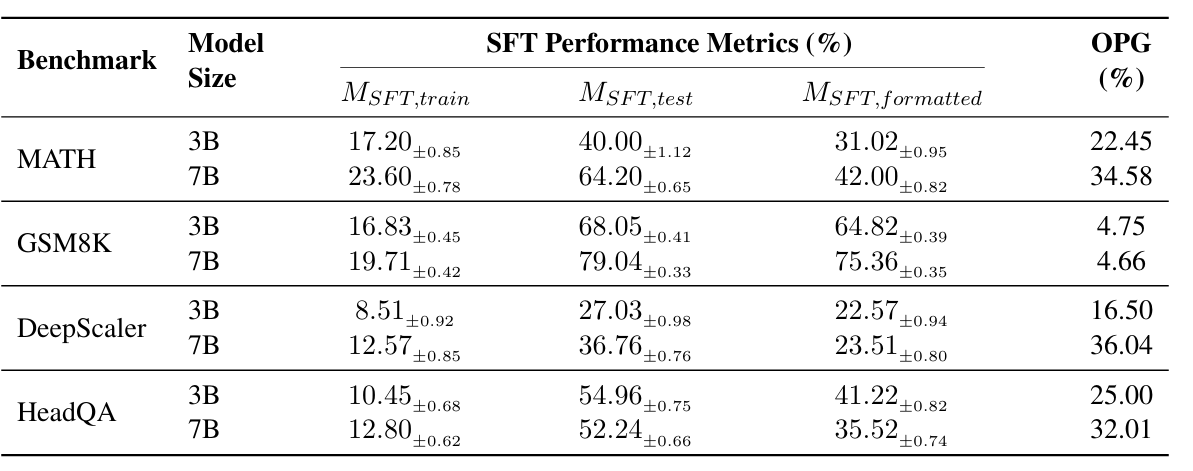
Table 2: SFT Generalization. Unlike RL, SFT models show a significant gap between standard training and Oracle performance, confirming the benchmarks pose a valid challenge for Supervised Fine-Tuning.
Benchmark Design Principles
Building on our analysis, we identify three key principles for effective RL generalization evaluation: testing cross-difficulty generalization, assessing distributional robustness, and probing counterfactual reasoning.
Principle 1: Stratify by Difficulty
The Paradox of Average Scores. A difficulty-agnostic evaluation masks substantial differences in generalization. Our analysis shows that models trained on easy data fail on hard tasks, yet their aggregated average scores remain deceptively similar to strong generalists. Therefore, benchmarks must report performance across difficulty levels separately.
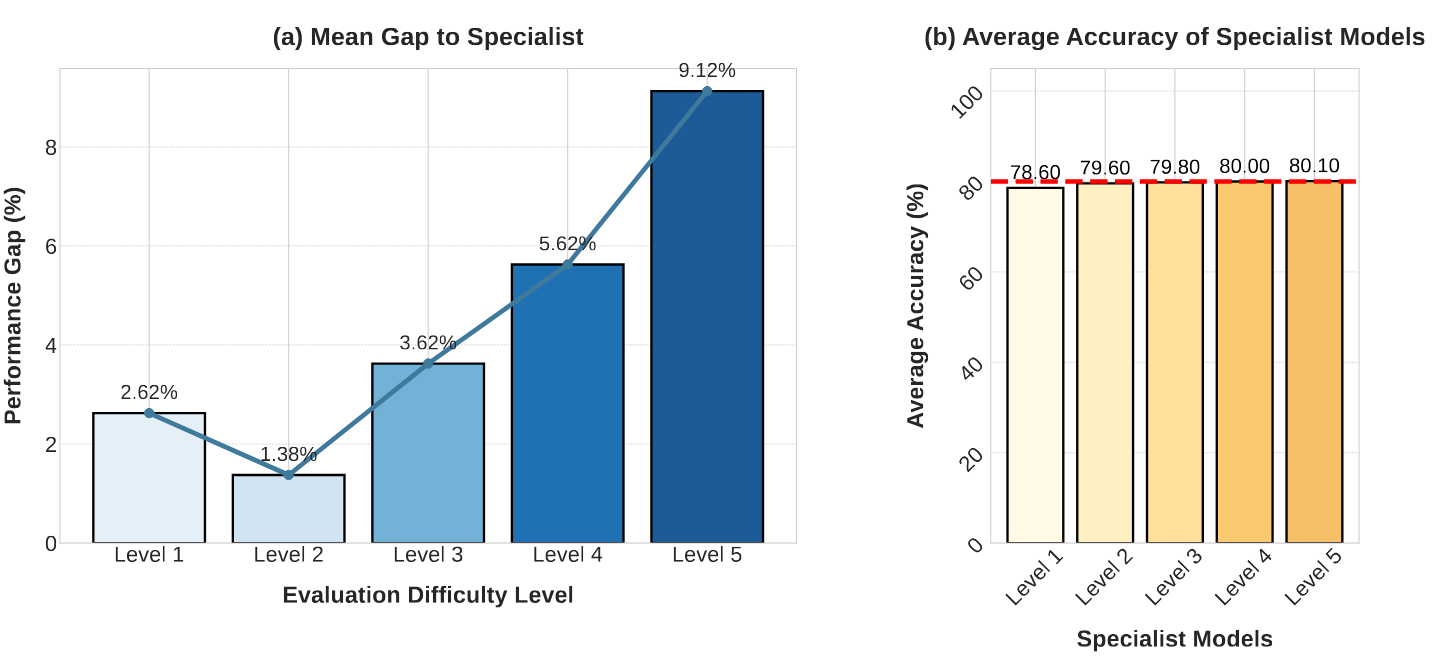
The Illusion of Average. (a) Stratified evaluation reveals widening gaps. (b) Average scores mask these failures.
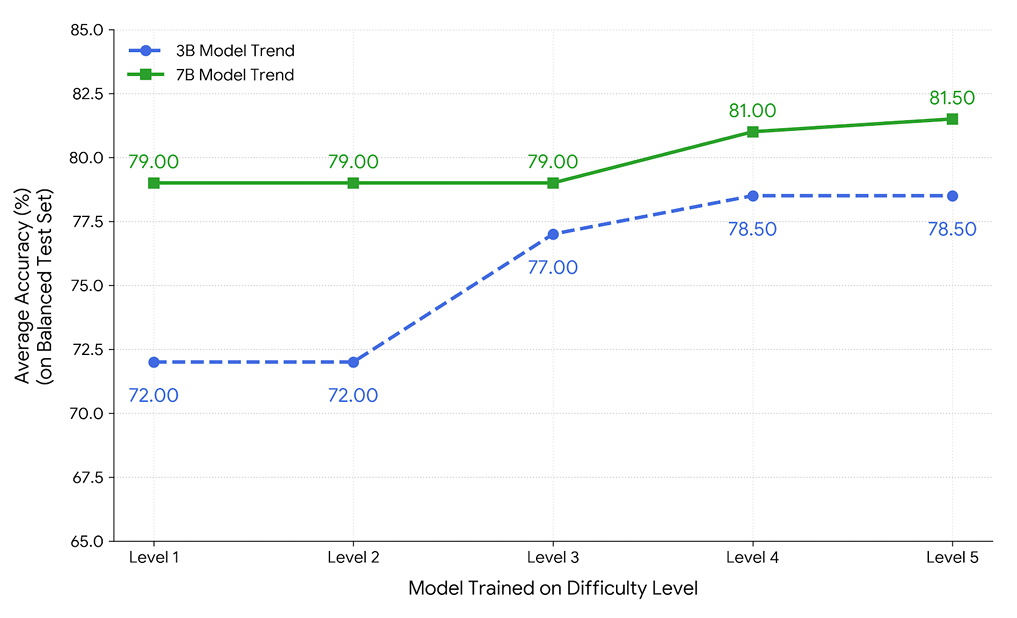
Training on Difficulty. Training on harder problems (L4-L5) boosts transferability.
Principle 2: Test Distributional Robustness
Finding: Performance Inversion. Fine-tuning on a narrow distribution (Mcore) leads to brittleness. As semantic distance increases (d1 → d5), the specialist's advantage vanishes and eventually turns into a penalty compared to the baseline. Benchmarks must include out-of-distribution (OOD) stress tests to penalize this brittleness.

Table 3: Performance Inversion. The specialist model (Mcore) excels locally but fails on OOD data (d5), performing worse than the baseline.
Principle 3: Probe Counterfactual Reasoning
Reasoning vs. Recitation. We distinguish true deduction from memorization by modifying problems to include counterfactual rules (e.g., changing the order of operations).
Finding: Models consistently default to reciting memorized priors rather than reasoning from the new premises. Performance collapses on the Counterfactual Set (Dcf) compared to the Balanced Set (Dbal), as shown in the table. Benchmarks require problems that create a direct conflict between priors and on-the-fly deduction.
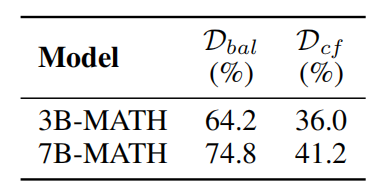
Table 4: Performance Collapse.